Я только что нашёл математику, которая гарантирует прибыль на Polymarket, и понял, почему розничные трейдеры по сути просто дают ликвидность. А под поверхностью платформы всё это время работал совсем другой слой реальности.
Я листал Twitter — хотя, наверное, уже должен был спать — и наткнулся на тред о человеке, который заработал $2 миллиона на торговле на Polymarket за один год. Не за счёт того, что правильно предсказал исход выборов. Не благодаря какому-то гениальному политическому инсайту. А за счёт чистой математики.
Сначала я подумал: ага, конечно, очередной крипто-парень, который преувеличивает свои результаты. Но потом я нашёл саму исследовательскую работу. Опубликованную, рецензируемую, с полным анализом данных. И то, что я там прочитал, не давало мне уснуть почти два часа, пока я пытался лучше понять рынки предсказаний.
Давай я объясню это так, как в итоге понял сам, потому что это действительно одна из самых захватывающих вещей, которые я вообще узнал.
$40 миллионов, о которых почти никто не говорит
Недавно вышла академическая работа — Unravelling the Probabilistic Forest, если захочешь потом загуглить, — в которой проанализировали абсолютно все транзакции на Polymarket с апреля 2024 по апрель 2025 года. Мы говорим о 86 миллионах транзакций. Полный год данных.
И то, что они нашли, оказалось безумным. Продвинутые трейдеры извлекли $40 миллионов гарантированной арбитражной прибыли. Не рискованных ставок, где можно и проиграть, а гарантированных денег, возникающих из математической определённости.
Один только топовый трейдер вытащил $2,009,632 из 4,049 сделок. Если посчитать, то это в среднем $496 прибыли на сделку. Не какие-то единичные «выстрелы». А последовательное, системное извлечение стоимости, которая по математике просто обязана была там быть.
И вот та часть, от которой я почувствовал себя слегка глупо: делали они это с помощью техник, которые уже много лет описаны в академических статьях. Ничего из этого не является секретом. Просто никто толком не удосужился реализовать это в масштабе.
А может, удосужился — и просто тихо заработал миллионы, пока все остальные спорили о рейтингах и результатах опросов.
Как я раньше представлял себе арбитраж на Polymarket
Прежде чем переходить к настоящей математике, расскажу, как я вообще раньше понимал арбитраж на Polymarket.
Ты находишь рынок, где YES торгуется по 55 центов, а NO — по 40 центов. В сумме получается 95 центов. Значит, можно купить оба варианта за 95 центов, а когда рынок рассчитается, один из них выплатит тебе $1. То есть ты просто делаешь 5 центов без риска.
Просто, правда?
Нужно всего лишь искать рынки, где числа не складываются в $1, и использовать это.
И знаешь что? Это действительно работает. Исследование показало, что таким способом было извлечено $10.6 миллиона. Но это очевидный уровень — если сформулировать точнее, это арбитраж для начинающих.
Настоящие деньги — остальные $29 миллионов — пришли из чего-то намного более сложного, о существовании чего большинство людей даже не знает.
Проблема Пенсильвании, которая меняет всё
Покажу на реальном примере с выборов 2024 года.

Ты листаешь Polymarket и видишь:
Рынок 1: победит ли Трамп в Пенсильвании?
- YES: 48 центов
- NO: 52 цента
- Итого: $1.00 ✓
Выглядит нормально. Идеально сбалансировано.
Рынок 2: победят ли республиканцы в Пенсильвании с отрывом 5+ пунктов?
- YES: 32 цента
- NO: 68 центов
- Итого: $1.00 ✓
Тоже идеально. Оба рынка по отдельности складываются корректно.
Значит, никакой арбитражной возможности нет, да? Оба рынка сбалансированы. Но если ты на этом месте просто идёшь дальше, то это и есть ошибка. И вот здесь становится интересно.
Подумай, о чём вообще спрашивают эти два рынка. Если республиканцы побеждают в Пенсильвании с отрывом 5 или более пунктов, это означает, что Трамп точно выиграл Пенсильванию. Невозможно, чтобы республиканцы выиграли штат с таким отрывом, а Трамп при этом проиграл. Это логически невозможно.
Эти рынки не независимы. Они связаны логикой.
А когда рынки связаны, но оцениваются так, как будто они независимы, деньги просто проваливаются в щели.
Давай разложим реальные возможные исходы:
- Трамп выигрывает, республиканцы выигрывают с отрывом 5+
- Трамп выигрывает, республиканцы выигрывают менее чем на 5
- Трамп проигрывает, республиканцы не выигрывают с отрывом 5+
Замечаешь, чего не хватает? Четвёртой комбинации — «Трамп проигрывает, но республиканцы выигрывают с отрывом 5+». Её не существует. Она невозможна.
Но когда ты оцениваешь эти рынки независимо, ты неявно предполагаешь, что все четыре комбинации возможны. В структуру рынка встроено скрытое предположение, которое не совпадает с реальностью.
Это называется dependency, то есть зависимость. И именно в нахождении таких зависимостей и лежат настоящие деньги.
Когда количество вариантов выходит за пределы человеческого понимания
Теперь ты, возможно, думаешь: «Ладно, я понял, некоторые рынки связаны. Значит, я просто буду смотреть пары рынков и проверять, нет ли там зависимости».
Хорошо. Удачи с этим.
Во время выборов 2024 года на Polymarket одновременно работало 305 разных рынков. Сколько возможных пар нужно проверить? 46,360 пар.
И это только пары. А некоторые арбитражные возможности включают три рынка. Или четыре. Или десять.
Давай разберём пример с турниром NCAA из исследования, потому что именно здесь мозг начинает плавиться.
Рынок на турнир NCAA 2010 года включал 63 игры. В каждой игре 2 возможных исхода: либо выигрывает команда A, либо команда B. Обычная турнирная сетка.
Сколько всего возможных комбинаций? 263.
Если записать это полностью, получится: 9,223,372,036,854,775,808 возможных исходов.
Более девяти квинтиллионов.
Если бы ты пытался проверить каждую комбинацию вручную — даже если предположить, что можешь проверять миллион комбинаций в секунду, — тебе понадобилось бы 292,471 год.
А турнир заканчивается за три недели.
Это то, что математики называют экспоненциальной сложностью. Именно поэтому обычный человеческий мозг и таблицы перестают работать, когда масштаб становится большим. Нужны алгоритмические подходы, которым не нужно перебирать все варианты.
Фокус с целочисленным программированием
Вот здесь продвинутые системы начинают делать действительно умную вещь.
Вместо того чтобы перечислять все возможные исходы, они описывают допустимые исходы через математические ограничения.
Вернёмся к примеру Duke vs Cornell из исследования. У каждой команды есть 7 разных бумаг, которые соответствуют количеству их побед: 0 побед, 1 победа, 2 победы и так далее вплоть до 6. Итого 14 условий.
Наивный подход: проверить все 214 = 16,384 возможных комбинации.
Умный подход: записать всего три простых правила.
- Правило 1: у Duke должен быть ровно один исход. Команда не может одновременно выиграть и 3 матча, и 5 матчей — должно быть только одно число.
- Правило 2: у Cornell тоже должен быть ровно один исход. Та же логика.
- Правило 3: Duke и Cornell не могут одновременно выиграть 5 или больше игр, потому что если бы обе команды дошли так далеко, они встретились бы в полуфинале, а значит, одна из них обязана была бы проиграть.
Три ограничения. И всё.
Современное ПО для оптимизации — например, Gurobi, которое использовали исследователи, — умеет решать такие проблемы за секунды. Ты больше не перебираешь 16,384 комбинации вручную. Ты позволяешь алгоритму найти, какие комбинации удовлетворяют твоим правилам.
Это и называется целочисленным программированием, и именно на этом держится поиск арбитража в масштабе.
Исследователи прогнали это на 17,218 условиях по всей Polymarket. Они нашли, что у 7,051 условий существовал single-market arbitrage. Это 41% всего, что они проанализировали.
Медианная ошибка ценообразования заключалась в том, что наборы рынков, которые должны были суммироваться к $1.00, в реальности суммировались к $0.60.
Вдумайся в это. Почти половина всех условий была неверно оценена в среднем на 40%. Polymarket была не просто слегка неэффективной. Она была масштабно, системно и глубоко эксплуатируемой.
Часть, где вероятность начинает вести себя странно
Итак, ты обнаружил, что арбитраж есть. Ты знаешь, что где-то внутри цен лежат «бесплатные» деньги. Что дальше?
Теперь нужно посчитать, какие именно сделки надо сделать. Сколько купить, сколько продать, какие конкретно условия брать.
И вот тут у большинства людей понимание полностью ломается, потому что ответ включает действительно странную математику.
Вот в чём главная проблема: рыночные цены — это не просто числа. Они представляют вероятности. А вероятности ведут себя странно.
Пример. Допустим, цена выросла с 50 до 60 центов. Это рост на 10 центов. Теперь представь другую цену, которая выросла с 5 до 15 центов. Тоже рост на 10 центов.
В обычной арифметике это одно и то же: оба движения равны +10 центов.
Но в терминах вероятности это совершенно разные вещи. Первое движение — это рост вероятности на 20% (с 50% до 60%). Второе — это рост на 200% (с 5% до 15%). Одно — небольшая коррекция. Другое — это «событие стало в три раза более вероятным».
Если ты пытаешься найти ближайший набор арбитражно-корректных цен к текущим рыночным ценам, ты не можешь просто использовать обычную метрику расстояния. Тебе нужна метрика, которая понимает, как устроены вероятности.
Именно это делает дивергенция Брэгмана.
Формула выглядит так:
D(μ||θ) = R(μ) + C(θ) — θ·μНе переживай из-за символов. По сути, эта формула измеряет информационное расстояние, то есть сколько информации теряется, когда ты переходишь от текущего состояния рынка (θ) к корректному арбитражно-свободному состоянию (μ).
И вот абсолютно дикая вещь, в которую я сам поверил только с третьего прочтения: максимальная гарантированная прибыль, которую можно извлечь из арбитража, в точности равна этой дивергенции Брэгмана.
Формула, которую доказали исследователи:
Maximum Profit = D(μ||θ)*Где μ* — ближайший арбитражно-свободный вектор цен.
Это означает, что поиск оптимальной арбитражной сделки — это не про интуицию и не про догадки. Это буквально вычислимое число. Можно точно посчитать, сколько прибыли математически доступно, и точно определить, какие сделки позволяют её извлечь.
Тот парень, который сделал $2 миллиона, просто вычислял это расхождение быстрее и точнее остальных, а потом исполнял сделки, на которые указывала математика.
Алгоритм Франк — Вульфа — алгоритм, который делает всё это возможным
Итак, тебе нужно вычислить эти дивергенции Брэгмана, чтобы найти μ*. Но тут появляется огромная проблема.
Множество всех допустимых арбитражно-свободных цен — математики называют его маргинальный полиэдр — имеет экспоненциальное число углов. Для турнира NCAA это буквально миллиарды и миллиарды углов.
Обычные алгоритмы оптимизации не умеют с таким работать. Им нужно видеть всё пространство, по которому они ищут решение, а это невозможно, когда пространство состоит из квинтиллионов точек.
И вот тут на сцену выходит алгоритм Франк — Вульфа, и он по-настоящему элегантен.
Вместо того чтобы пытаться обрабатывать всё пространство целиком, Франк — Вульф итеративно собирает маленький рабочий набор точек. Процесс выглядит так:
- Шаг 1: начинаешь с нескольких известных корректных векторов цен. Скажем, с 5 или 10 точек.
- Шаг 2: решаешь задачу оптимизации только на этих точках. Это легко, потому что набор маленький.
- Шаг 3: задаёшь вопрос: «Если я могу добавить в набор ещё одну точку, какая даст максимальное улучшение?» Эту точку находят, решая один целочисленную программу.
- Шаг 4: добавляешь найденную точку в рабочий набор.
- Шаг 5: повторяешь шаги 2–4, пока решение перестаёт заметно улучшаться.
Гениальность в том, что тебе никогда не нужно перечислять всё пространство целиком. Ты наращиваешь ровно те точки, которые действительно нужны, по одной за раз, и сама оптимизация подсказывает, какие именно.
Исследование показывает, что обычно такой процесс сходится за 50–150 итераций. Каждая итерация занимает от 1 до 30 секунд в зависимости от сложности рынка.
То есть даже для сложного рынка ты получаешь ответ меньше чем за час. А чаще — намного быстрее.
Этого достаточно, чтобы извлечь арбитраж до того, как цены успеют измениться.
Как на практике выглядела система, которая вытащила $40 миллионов
Теперь давай разберём, что именно на самом деле построили эти трейдеры. Не абстрактную теорию, а реальную реализацию.

Конвейер данных
Во-первых, тебе нужны данные. И не просто данные, а данные в реальном времени.
Они использовали WebSocket-соединения к CLOB API Polymarket (Central Limit Order Book). Это даёт:
- каждое изменение цены в ту же секунду, когда оно произошло;
- изменения объёма;
- каждую исполненную сделку;
- создание новых рынков;
- расчёт и закрытие рынков.
Ты не обновляешь страницу браузера каждые 30 секунд. Ты получаешь поток обновлений в реальном времени с задержкой менее 3 секунд.
Кроме того, они тянули исторические данные из блокчейна. Polymarket работает на Polygon, и каждая сделка записывается в блокчейн. Исследователи проанализировали 86 миллионов транзакций. Для этого нужна серьёзная инфраструктура баз данных, а не Excel.
Слой выявления зависимостей
Помнишь 46,360 возможных пар рынков во время выборов? Ты не можешь вручную анализировать, какие из них содержат зависимости.
Поэтому они использовали AI-модель. Конкретно — DeepSeek-R1-Distill-Qwen-32B, то есть большую языковую модель, хорошо приспособленную к рассуждению.
На вход: описание двух рынков.
На выход: JSON-файл, в котором перечислены комбинации исходов, которые реально допустимы.
ИИ читал, например, «Победит ли Трамп в Пенсильвании?» и «Победят ли республиканцы в Пенсильвании с отрывом 5+ пунктов?» и выдавал что-то вроде:
Допустимые исходы:
- Trump YES, Republicans 5+ YES
- Trump YES, Republicans 5+ NO
- Trump NO, Republicans 5+ NO
Недопустимые исходы:
- Trump NO, Republicans 5+ YES (невозможно)
На сложных рынках с несколькими условиями модель показывала точность 81%. Не идеально, но вполне достаточно, чтобы отфильтровать тысячи пар до сотен, которые потом можно проверить вручную.
Из 46,360 пар они нашли 1,576 потенциально зависимых. Затем вручную проверили их и подтвердили, что 13 действительно дают exploitable guaranteed arbitrage.
Оптимизационный движок
Три слоя, работающие последовательно.
Слой 1: быстрые линейные проверки
Самые базовые проверки корректности:
- суммируются ли вероятности к 1;
- если рынок A логически влечёт рынок B, выполняется ли P(A) ≤ P(B).
Это простые линейные проверки, которые работают за миллисекунды. Они ловят очевидные ошибки ещё до того, как ты тратишь вычислительные ресурсы на более сложные вещи.
Слой 2: настоящая работа
Вот здесь запускается алгоритм Франк — Вульфа вместе с дивергенцией Брэгмана.
Параметры, которые использовали исследователи:
- Alpha = 0.9 — извлекать как минимум 90% доступного арбитража, оставляя 10% как буфер под execution risk;
- Initial epsilon = 0.1 — начальное сжатие доступного множества на 10%;
- Convergence threshold = 0.000001 — остановка, когда улучшение становится совсем маленьким;
- Time limit = 30 minutes per market — ограничение в 30 минут на рынок, которое уменьшалось по мере упрощения рынков.
На практике это означало 50–150 итераций и завершение за несколько минут для большинства рынков.
Слой 3: валидация исполнения
Прежде чем выставлять реальные ордера, они симулировали их исполнение против текущего order book.
Нужно было ответить на вопросы:
- хватит ли ликвидности на этих ценах;
- какой ожидается slippage — насколько крупный ордер сдвинет цену против тебя;
- какова гарантированная прибыль после slippage и комиссий;
- превышает ли прибыль минимальный порог — они использовали 5 центов.
Только если все проверки проходили успешно, система исполняла сделку. Нет смысла ставить теоретически прибыльный ордер, который не сработает на практике.
Размер позиции
Они использовали модифицированный критерий Келли, который учитывал риск исполнения:
f = (b×p — q) / b × sqrt(p)Где:
- b = процент арбитражной прибыли;
- p = вероятность получить исполнение по ожидаемой цене (оценивалась по глубине стакана);
- q = 1 − p.
Кроме того, они ограничивали любую позицию 50% от текущей глубины стакана, чтобы не двигать рынок слишком сильно.
Это уже не гэмблинг. Это количественный риск-менеджмент.
Система мониторинга
У них был дашборд реального времени, который отслеживал:
- сколько возможностей найдено в минуту;
- сколько возможностей исполнено в минуту;
- коэффициент успешного исполнения;
- общую прибыль — накопительным итогом;
- текущая просадка в процентах;
- среднюю задержку от обнаружения возможности до отправки ордера.
И отдельные алерты на случаи, если:
- просадка превышала 15%;
- процент исполнения падал ниже 30%;
- решатель целочисленного программирования начинал упираться в тайм аут;
- резко возрастало число неисполненных ордеров.
Топовый трейдер сделал 4,049 транзакций за год. Это примерно 11 сделок в день. По меркам Уолл-стрит это не высокачастотный трейдинг, но это системная и очень последовательная работа.
Фактические результаты — приготовься почувствовать кое-что
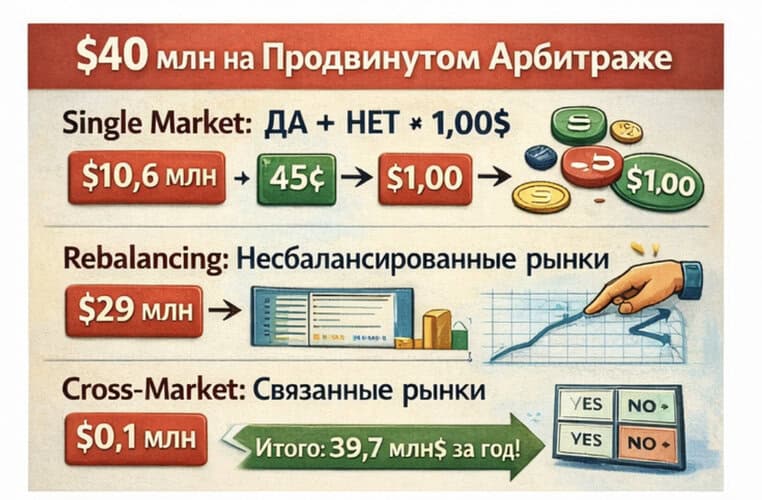
Итак, вот что реально было извлечено с апреля 2024 по апрель 2025:
Арбитраж по одной условию
Это простейшие рынки, где YES + NO ≠ $1.
- Покупка обоих вариантов, когда суммарно они стоят меньше $1: $5,899,287
- Продажа обоих вариантов, когда суммарно они стоят больше $1: $4,682,075
- Итого: $10,581,362
Ребалансировка рынка
Рынки с несколькими условиями, которые внутренне неверно оценены.
- Покупка всех YES, когда их сумма меньше $1: $11,092,286
- Продажа всех YES, когда их сумма больше $1: $612,189
- Покупка всех NO: $17,307,114
- Итого: $29,011,589
Комбинаторный арбитраж
Это кросс-рыночные зависимости, то есть ситуации типа пенсильванского примера.
- $95,634
Общий итог
$39,688,585
Почти $40 миллионов за один год.
Топ-10 трейдеров извлекли $8,127,849 — это 20.5% от всей суммы.
Один только топовый трейдер: $2,009,632 из 4,049 сделок.
Средняя прибыль на сделку: $496.
Это системное математическое извлечение стоимости, повторённое тысячи раз.
Две совершенно разные игры, которые идут одновременно

Сейчас я нарисую тебе картину того, что на самом деле происходит на Polymarket.
Розничный трейдер
Ты просыпаешься, читаешь новости. Вышли новые опросы, где Трамп лидирует в Мичигане. Ты думаешь: «Хм, его шансы должны вырасти».
Открываешь Polymarket на телефоне. Смотришь рынок по Мичигану. Трамп стоит 52 цента. Кажется дешево с учётом новых опросов.
Покупаешь YES на Трампа на $100.
Потом возвращаешься к рынку каждые несколько часов, чтобы посмотреть, сдвинулась ли цена. Может быть, ты заработаешь $20, если окажешься прав. Может быть, потеряешь $100, если ошибёшься.
Ты играешь в ту игру, которой, как тебе кажется, и является Polymarket: делаешь ставки на политические исходы на основе своей интерпретации новостей.
Высокочастотный трейдер
4:32 утра. Твой сервер получает обновление цены через WebSocket.
За 0.8 секунды твоя система:
- сканирует 305 активных рынков на предмет нарушения зависимостей;
- находит 3 пары рынков со структурной неверной оценкой;
- вычисляет дивергенции Брэгмана для каждой пары через алгоритма Франк — Вульфа;
- считает оптимальный размер позиций с учётом текущей ликвидности;
- симулирует исполнение по стакану;
- определяет ожидаемую прибыль после slippage.
Одна из возможностей показывает $127 гарантированной прибыли. Вероятность успешного исполнения: 94%.
Твоя система одновременно отправляет 6 ордеров по 3 рынкам.
Все ордера исполняются в течение 2 секунд.
Прибыль: $124 — чуть ниже прогноза из-за небольшого slippage.
Полное время от обнаружения возможности до исполнения: 2.65 секунды.
Ты играешь уже в совершенно другую игру: эксплуатируешь математические неэффективности в структуре цен.
Вы оба используете одну и ту же платформу. Но по сути это даже не один и тот же вид спорта.
Почему всё это ощущается немного некомфортно
Вот что меня во всём этом по-настоящему беспокоит.
Вся математика, о которой я только что рассказал, публична. Алгоритмы опубликованы ещё в работах 2016 года. Gurobi даёт бесплатные академические лицензии. API Polymarket полностью задокументирован.
Ничего из этого не секретно. Ничего не незаконно. Ничего не связано с инсайдом.
И всё же 99.9% пользователей Polymarket вообще не понимают, что это происходит.
Они думают, что делают информированные ставки на политические события. Смотрят новости. Изучают опросы. Чувствуют себя умными, когда правильно угадывают.
А в это время алгоритмы вытаскивают миллионы гарантированной прибыли из структурных неэффективностей, о существовании которых эти люди даже не знают.
Это не мошенничество. Не манипуляция. Это просто математика.
Но из-за этого возникает странная двухуровневая система, где обычные пользователи по сути просто поставляют ликвидность для количественных систем, которые извлекают из неё стоимость.
Знаешь, что мне это напоминает?
Покер начала 2000-х. Несколько лет, если ты изучал равновесную стратегию, ты мог системно зарабатывать на игроках, которые играли по интуиции. Потом все выучили оптимальную по теории игр, и преимущество исчезло.
Мне кажется, Polymarket сейчас находится именно в этой фазе. Неэффективности огромны — напомню, 41% условий содержали арбитраж, — потому что рынок ещё молодой, и большинство участников вообще не знает, что такая математика существует.
Но это не продлится вечно. Чем больше в рынок придёт продвинутых игроков, тем сильнее сожмутся маржи. Лёгкие деньги исчезнут.
Скорее всего, мы прямо сейчас в реальном времени наблюдаем золотой век арбитража на рынках предсказаний. И большинство людей понятия об этом не имеет.
Философская странность всего происходящего
Во всей этой истории есть что-то более глубокое, о чём я никак не перестану думать.
Вся ценность Polymarket строится на идее мудрости толпы — на том, что объединение большого числа человеческих прогнозов даёт точный результат.
Но что, если толпа системно теряет капитал в пользу алгоритмов, которые эксплуатируют математическую структуру рынка?
Это делает цены более точными или менее точными?
С одной стороны, удаление арбитража должно подталкивать цены к эффективности. Если YES и NO торгуются по 55 и 40 центов, арбитражёры, покупая оба варианта, будут толкать рынок обратно к 50/50, пока сумма не станет равной $1.
Но с другой стороны, если люди с наибольшим капиталом и наибольшей вычислительной мощностью ставят не на основе политического знания, а на основе математической структуры, то, возможно, мы получаем очень точные цены в смысле структурной согласованности, но не обязательно в смысле истинной вероятности.
То есть, возможно, рынок оценивает шансы Трампа в 58% не потому, что это реальная вероятность победы, а потому, что именно на этой отметке все кросс-рыночные ограничения выравниваются, и арбитражёры больше не могут извлечь прибыль.
У меня нет ответа на этот вопрос. Но думать об этом очень интересно.
Что будет дальше
Мне кажется, мы находимся в точке перегиба.
Прямо сейчас Polymarket настолько неэффективна, что на ней существует $40 миллионов арбитража. Но каждый извлечённый доллар делает рынок немного эффективнее. Каждый новый высокочастотный трейдер, который приходит в систему, сильнее сжимает маржу.
Я готов поспорить, что через пять лет большинство таких возможностей почти исчезнет. Продвинутые системы «натренируют» рынок. Цены начнут схлопываться к арбитражно-свободным состояниям за секунды.
И что потом?
Потом Polymarket станет похожа на любой другой зрелый финансовый рынок — ультраэффективный, с бритвенно тонкими маржами, где доминирует тот, у кого самая быстрая инфраструктура.
Но вот что мне кажется особенно интересным: тот же самый математический аппарат не только находит арбитраж. Он вскрывает структуру.
Если ты умеешь моделировать зависимости между рынками, ты можешь:
- предсказывать, какие события обычно двигаются вместе;
- определять, когда рынок слишком сильно реагирует на новости относительно структурных ограничений;
- находить неверно оценённые события, которые все игнорируют;
- строить портфели, которые хеджируют риски предсказаний сразу по нескольким исходам.
Эта математика показывает тебе отношения между событиями, которые неочевидны, если просто читать новости.
Например, возможно, модель обнаруживает, что решения ФРС по ставкам, динамика тех-акций и исходы выборов образуют очень плотный dependency cluster и почти всегда двигаются вместе. Это уже alpha даже без чистого арбитража.
Если бы ты реально захотел это построить
Предположим, ты настолько безумен, что действительно хочешь собрать что-то подобное. Что тебе реально понадобится?
Математическая база
Тебе нужно по-настоящему понимать:
- Выпуклая оптимизация: учебник Стивена Бойда и Ливена Ванденберге — стандарт по теме. Тяжёлый, но очень полный.
- Целочисленное программирование: как формулировать задачи в виде линейных ограничений.
- Теория вероятностей: сильно дальше базовой статистики. Information theory, divergences, proper scoring rules.
- Вычислительная сложность: понимание, когда задача решаема, а когда она уходит в экспоненциальный ад.
Это не чтение на выходные. Это месяцы обучения.
Навыки программирования
- Python: обработка данных, реализация алгоритмов, работа с API;
- WebSocket programming: real-time data feeds;
- Database management: работа с миллионами транзакций, вероятнее всего через PostgreSQL;
- Optimization libraries: Gurobi (дорогой) или open-source альтернативы вроде COIN-OR.
Тебе нужно уметь писать качественный код, который работает 24/7 и не разваливается.
Понимание рыночной инфраструктуры
- как реально устроены рынки предсказаний — LMSR vs CLOB механизмы;
- динамика книги ордеров;
- стратегии исполнения;
- риск менеджмент;
- микроструктура рынка.
Это приходит через чтение академических статей и, вероятно, через потерю некоторого количества денег в процессе обучения.
Вычислительные ресурсы
- серверы, которые могут гонять оптимизационные алгоритмы почти в реальном времени;
- базы данных, которые не умирают на миллионах строк;
- инфраструктура мониторинга и алертов;
- резервные системы на случай, когда что-то ломается.
Топовый трейдер, вероятно, потратил на инфраструктуру тысячи долларов. Возможно, десятки тысяч.
Затраты времени
Исследовательская статья оценивает, что топовые системы, скорее всего, потребовали 500+ часов на разработку и доводку.
Это три месяца работы на полную ставку.
И это при условии, что ты уже знаешь математику и умеешь кодить. Если начинаешь с нуля — умножай на 3 или 4.
Настоящий урок
Я понимаю, что только что вывалил на тебя много математики. Возможно, слишком много. Но вот что реально важно.
Polymarket — это не просто место, где люди ставят на политику. Это сложная математическая система, которой управляют отношения между событиями, невидимые для большинства участников.
Интерфейс простой: нажал YES или NO, рискнул деньгами, возможно выиграл.
Но под ним скрыт целый слой математической структуры: зависимости между событиями, задачи оптимизации в пространствах высокой размерности, информационно-теоретические меры расстояния, удовлетворение ограничений.
И люди, которые понимают этот слой, извлекают миллионы, пока все остальные просто ставят на новости.
Разрыв между этими двумя мирами огромен. И большинство людей никогда его не пересечёт, потому что для этого нужны месяцы сложной математики, сотни часов кодинга, тысячи долларов на инфраструктуру и готовность относиться к рынкам предсказаний как к задачам оптимизации, а не как к политическому беттингу.
Для 99% пользователей Polymarket — это именно то, чем она кажется: интересный способ ставить реальные деньги на события, которые тебе небезразличны. И это тоже нормально. Это абсолютно валидный способ пользоваться платформой.
Но для того 1%, кто видит математическую структуру под поверхностью?
$40 миллионов за один год говорят, что математику точно стоит изучить.
Исследовательская статья публична. Алгоритмы опубликованы. Инструменты существуют.
Остаётся только один вопрос: готов ли ты вложить достаточно труда, чтобы реально это построить?
Потому что вот о чём обычно никто не говорит: знание само по себе не является ограничением. Математика доступна бесплатно. Редкость — это комбинация математического понимания + навыков программирования + знания рынка + инфраструктурных ресурсов + долгой и системной работы по реальной реализации.
Именно эта комбинация и сделала $2 миллиона.
И, если честно, я много об этом думаю. О том, насколько успех в любой области часто сводится просто к готовности копнуть глубже, чем готовы копать остальные.
Большинство людей видит в Polymarket просто платформу для ставок.
Некоторые видят prediction market.
И только немногие видят задачу оптимизации в пространстве высокой размерности со структурными неэффективностями, которые можно эксплуатировать.
Именно эти немногие и сделали $40 миллионов.
Математика всегда была там. Возможности всегда были там. Они просто проделали работу, которую никто другой не захотел делать.
И теперь ты тоже знаешь, что это существует. Вопрос только в том, что ты сделаешь с этой информацией.
Что я бы еще добави
Главный вывод здесь не в том, что «на Polymarket есть бесплатные деньги», а в том, что на молодых рынках почти всегда существует слой структурной неэффективности, который не виден обычному пользователю. Большинство людей торгует новости, эмоции и нарративы. Небольшая часть торгует архитектуру рынка.
И именно поэтому рынки предсказаний интересны не только как площадка для ставок, но и как лаборатория для количественного мышления. Здесь пересекаются теория вероятностей, рыночная микроструктура, машинное обучение, оптимизация и поведенческие искажения толпы.